Fooocus:AI 生成图片工具库

Fooocus is an image generating software (based on Gradio).
Fooocus is a rethinking of Stable Diffusion and Midjourney’s designs:
- Learned from Stable Diffusion, the software is offline, open source, and free.
- Learned from Midjourney, the manual tweaking is not needed, and users only need to focus on the prompts and images.
Fooocus has included and automated lots of inner optimizations and quality improvements. Users can forget all those difficult technical parameters, and just enjoy the interaction between human and computer to "explore new mediums of thought and expanding the imaginative powers of the human species" [1].
Fooocus has simplified the installation. Between pressing "download" and generating the first image, the number of needed mouse clicks is strictly limited to less than 3. Minimal GPU memory requirement is 4GB (Nvidia).
Fooocus also developed many "fooocus-only" features for advanced users to get perfect results. Click here to browse the advanced features.
[1] David Holz, 2019.
Download
Windows
You can directly download Fooocus with:
>>> Click here to download <<<
After you download the file, please uncompress it, and then run the "run.bat".
In the first time you launch the software, it will automatically download models:
- It will download sd_xl_base_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_base_1.0_0.9vae.safetensors".
- It will download sd_xl_refiner_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_refiner_1.0_0.9vae.safetensors".
- Note that if you use inpaint, at the first time you inpaint an image, it will download Fooocus's own inpaint control model from here as the file "Fooocus\models\inpaint\inpaint.fooocus.patch" (the size of this file is 1.28GB).

If you already have these files, you can copy them to the above locations to speed up installation.
Note that if you see "MetadataIncompleteBuffer", then your model files are corrupted. Please download models again.
Below is a test on a relatively low-end laptop with 16GB System RAM and 6GB VRAM (Nvidia 3060 laptop). The speed on this machine is about 1.35 seconds per iteration. Pretty impressive – nowadays laptops with 3060 are usually at very acceptable price.
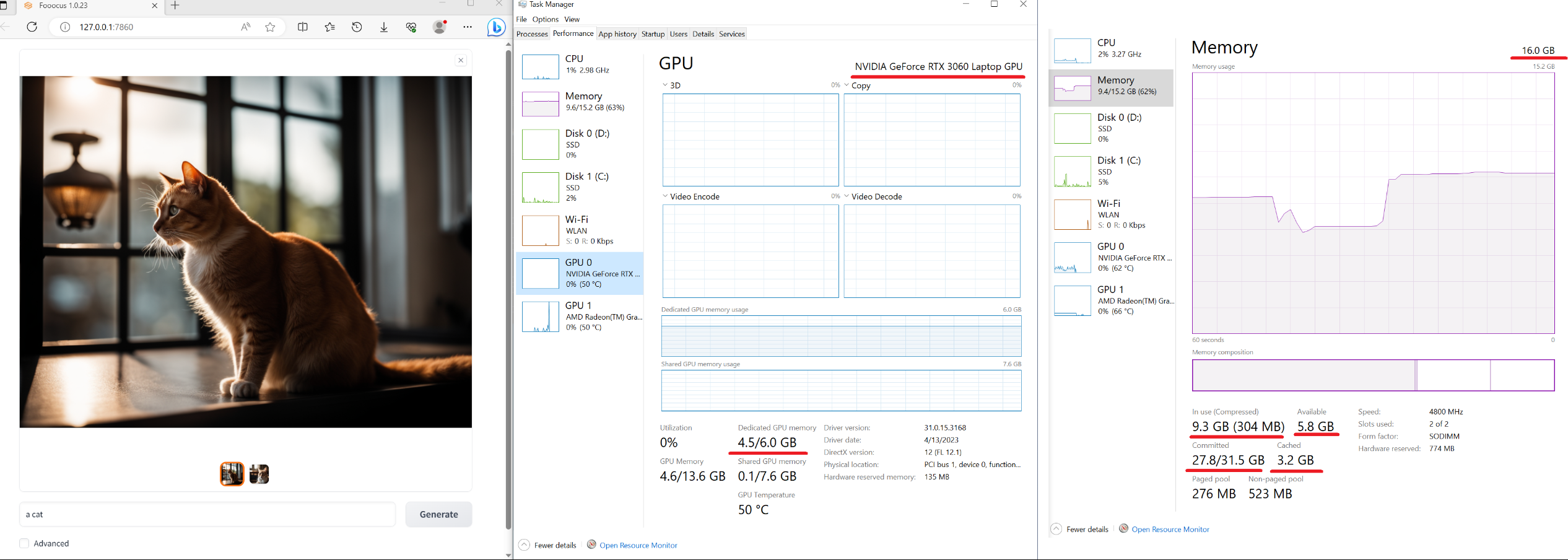
Besides, recently many other software report that Nvidia driver above 532 is sometimes 10x slower than Nvidia driver 531. If your generation time is very long, consider download Nvidia Driver 531 Laptop or Nvidia Driver 531 Desktop.
Note that the minimal requirement is 4GB Nvidia GPU memory (4GB VRAM) and 8GB system memory (8GB RAM). This requires using Microsoft’s Virtual Swap technique, which is automatically enabled by your Windows installation in most cases, so you often do not need to do anything about it. However, if you are not sure, or if you manually turned it off (would anyone really do that?), or if you see any "RuntimeError: CPUAllocator", you can enable it here:
<details>
<summary>Click here to the see the image instruction. </summary>
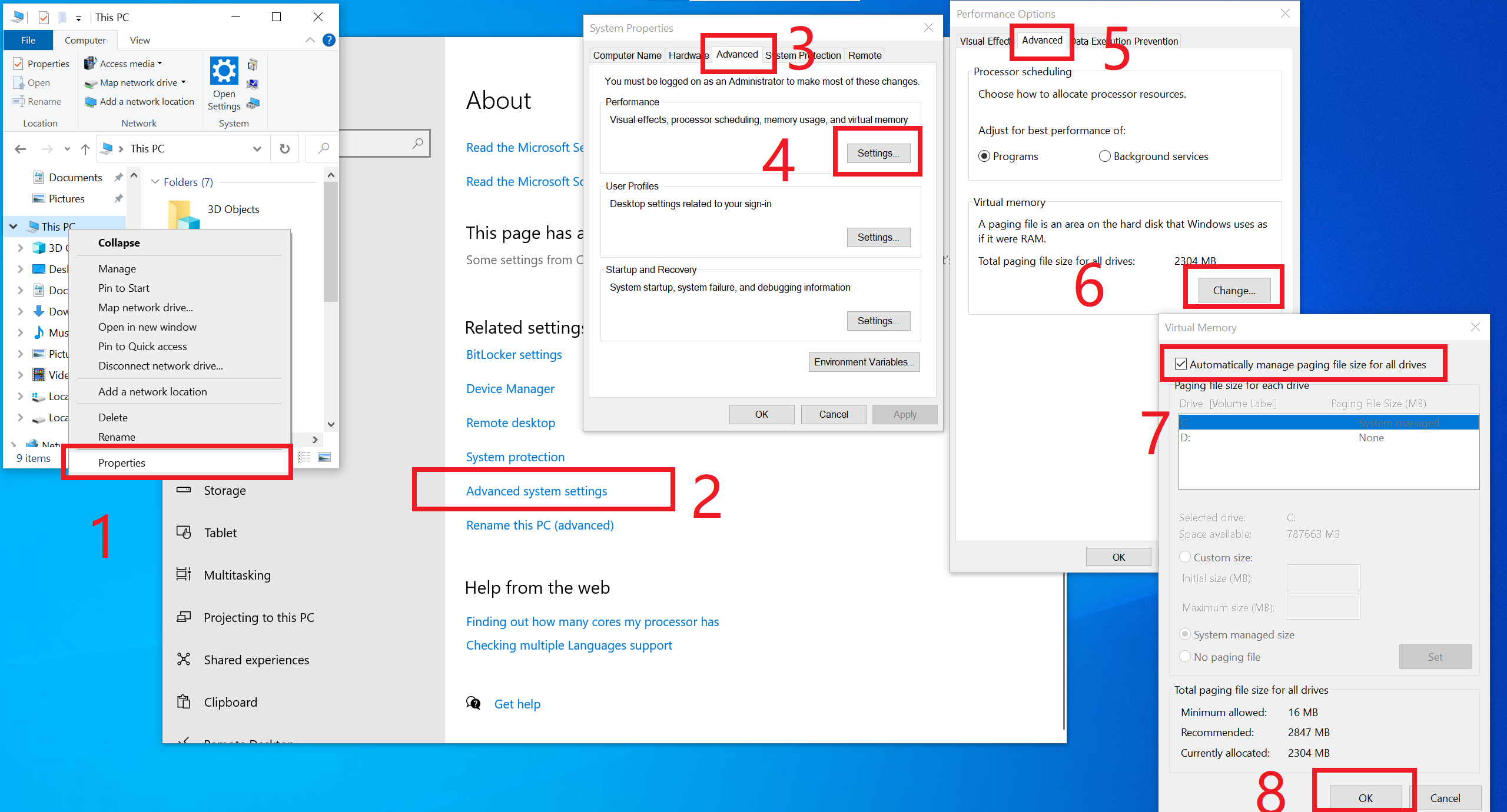
And make sure that you have at least 40GB free space on each drive if you still see "RuntimeError: CPUAllocator" !
</details>
Please open an issue if you use similar devices but still cannot achieve acceptable performances.
Colab
(Last tested - 2023 Sep 13)
| Colab | Info |
|---|
 | Fooocus Colab (Official Version) |
Thanks to camenduru!
Linux (Using Anaconda)
If you want to use Anaconda/Miniconda, you can
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
conda env create -f environment.yaml
conda activate fooocus
pip install pygit2==1.12.2
Then download the models: download sd_xl_base_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_base_1.0_0.9vae.safetensors", and download sd_xl_refiner_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_refiner_1.0_0.9vae.safetensors". Or let Fooocus automatically download the models using the launcher:
conda activate fooocus
python entry_with_update.py
Or if you want to open a remote port, use
conda activate fooocus
python entry_with_update.py --listen
Linux (Using Python Venv)
Your Linux needs to have Python 3.10 installed, and lets say your Python can be called with command python3 with your venv system working, you can
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
python3 -m venv fooocus_env
source fooocus_env/bin/activate
pip install pygit2==1.12.2
See the above sections for model downloads. You can launch the software with:
source fooocus_env/bin/activate
python entry_with_update.py
Or if you want to open a remote port, use
source fooocus_env/bin/activate
python entry_with_update.py --listen
Linux (Using native system Python)
If you know what you are doing, and your Linux already has Python 3.10 installed, and your Python can be called with command python3 (and Pip with pip3), you can
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
pip3 install pygit2==1.12.2
See the above sections for model downloads. You can launch the software with:
python3 entry_with_update.py
Or if you want to open a remote port, use
python3 entry_with_update.py --listen
Linux (AMD GPUs)
本站注:AMD
TORCH_INDEX_URL=https://download.pytorch.org/whl/rocm5.4.2 python entry_with_update.py
Installation is the same as Linux part. It has been tested for 6700XT. Works for both Pytorch 1.13 and Pytorch 2.
Mac/Windows(AMD GPUs)
Coming soon ...
List of "Hidden" Tricks
<a name="tech_list"></a>
Below things are already inside the software, and users do not need to do anything about these.
- GPT2-based prompt expansion as a dynamic style "Fooocus V2". (similar to Midjourney's hidden pre-processsing and "raw" mode, or the LeonardoAI's Prompt Magic).
- Native refiner swap inside one single k-sampler. The advantage is that now the refiner model can reuse the base model's momentum (or ODE's history parameters) collected from k-sampling to achieve more coherent sampling. In Automatic1111's high-res fix and ComfyUI's node system, the base model and refiner use two independent k-samplers, which means the momentum is largely wasted, and the sampling continuity is broken. Fooocus uses its own advanced k-diffusion sampling that ensures seamless, native, and continuous swap in a refiner setup. (Update Aug 13: Actually I discussed this with Automatic1111 several days ago and it seems that the “native refiner swap inside one single k-sampler” is merged into the dev branch of webui. Great!)
- Negative ADM guidance. Because the highest resolution level of XL Base does not have cross attentions, the positive and negative signals for XL's highest resolution level cannot receive enough contrasts during the CFG sampling, causing the results look a bit plastic or overly smooth in certain cases. Fortunately, since the XL's highest resolution level is still conditioned on image aspect ratios (ADM), we can modify the adm on the positive/negative side to compensate for the lack of CFG contrast in the highest resolution level. (Update Aug 16, the IOS App Drawing Things will support Negative ADM Guidance. Great!)
- We implemented a carefully tuned variation of the Section 5.1 of "Improving Sample Quality of Diffusion Models Using Self-Attention Guidance". The weight is set to very low, but this is Fooocus's final guarantee to make sure that the XL will never yield overly smooth or plastic appearance (examples here). This can almostly eliminate all cases that XL still occasionally produce overly smooth results even with negative ADM guidance. (Update 2023 Aug 18, the Gaussian kernel of SAG is changed to an anisotropic kernel for better structure preservation and fewer artifacts.)
- We modified the style templates a bit and added the "cinematic-default".
- We tested the "sd_xl_offset_example-lora_1.0.safetensors" and it seems that when the lora weight is below 0.5, the results are always better than XL without lora.
- The parameters of samplers are carefully tuned.
- Because XL uses positional encoding for generation resolution, images generated by several fixed resolutions look a bit better than that from arbitrary resolutions (because the positional encoding is not very good at handling int numbers that are unseen during training). This suggests that the resolutions in UI may be hard coded for best results.
- Separated prompts for two different text encoders seem unnecessary. Separated prompts for base model and refiner may work but the effects are random, and we refrain from implement this.
- DPM family seems well-suited for XL, since XL sometimes generates overly smooth texture but DPM family sometimes generate overly dense detail in texture. Their joint effect looks neutral and appealing to human perception.
- A carefully designed system for balancing multiple styles as well as prompt expansion.
- Using automatic1111's method to normalize prompt emphasizing. This significantly improve results when users directly copy prompts from civitai.
- The joint swap system of refiner now also support img2img and upscale in a seamless way.
Advanced Features
Click here to browse the advanced features.
Thanks
The codebase starts from an odd mixture of Automatic1111 and ComfyUI. (And they both use GPL license.)
https://github.com/lllyasviel/Fooocus




